
Analysieren von Smartphone-Nutzungsdaten mit R - Teil 1: App-Sessions
Wir zeigen dir in dieser Anleitung, wie du App-Nutzungsdaten der Murmuras-Plattform in R analysierst. Du wirst lernen:
1. die meistgenutzten Apps in deiner Stichprobe zu identifizieren,
2. die App-Nutzung von Frauen und Männern zu vergleichen,
3. und die durchschnittliche monatliche App-Nutzungsdauer von WhatsApp, Instagram und Youtube grafisch darzustellen.
Wir verwenden RStudio als Arbeitsumgebung. Wenn du in RStudio mitarbeiten möchtest, lade einfach diese Zip-Datei mit der Rmd-Datei und den Übungsdatensätzen runter, kopier sie in dein Projektverzeichnis und öffnen sie in RStudio.
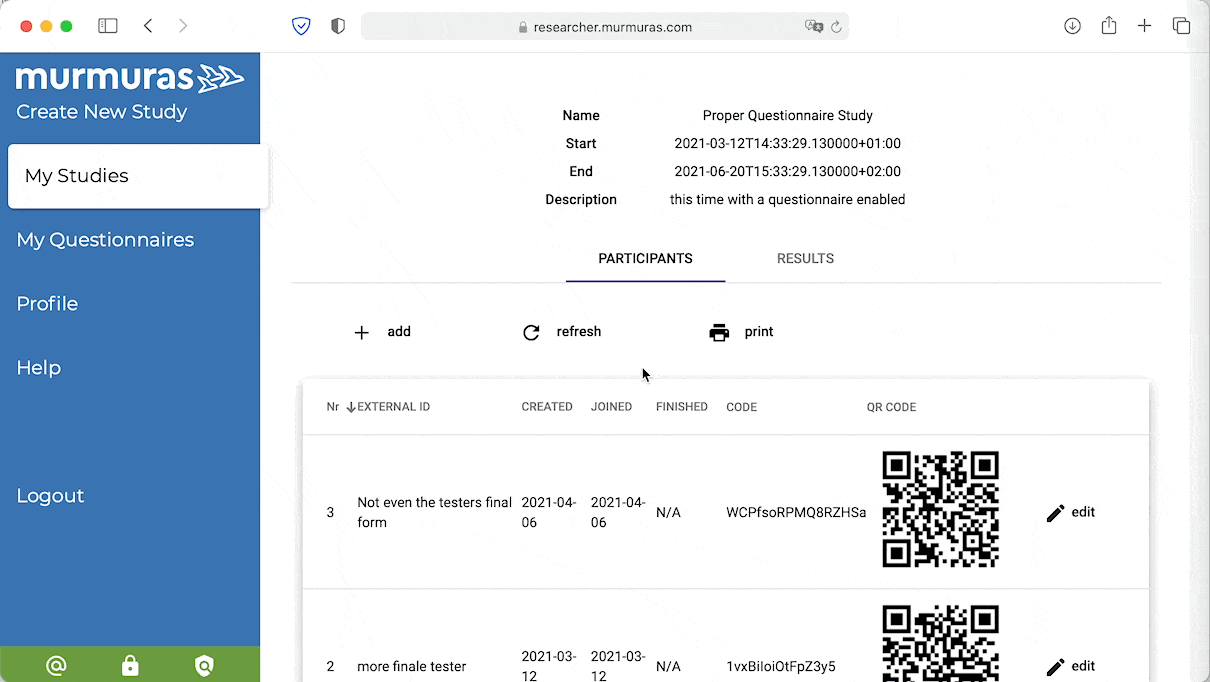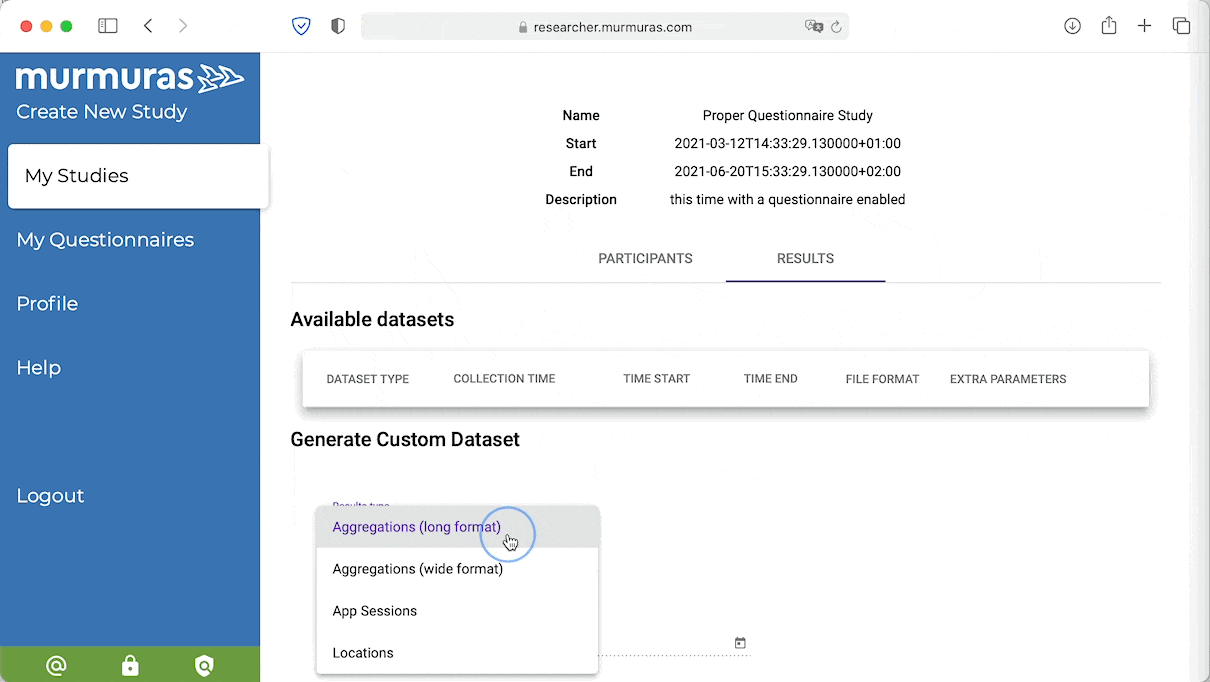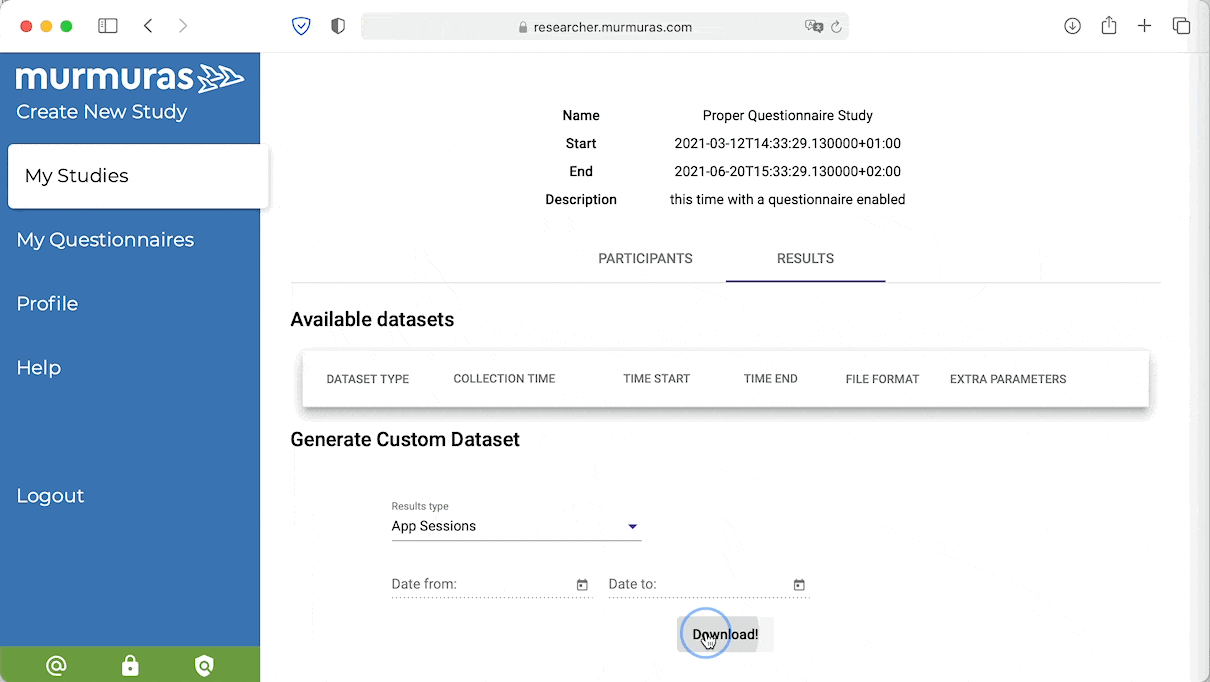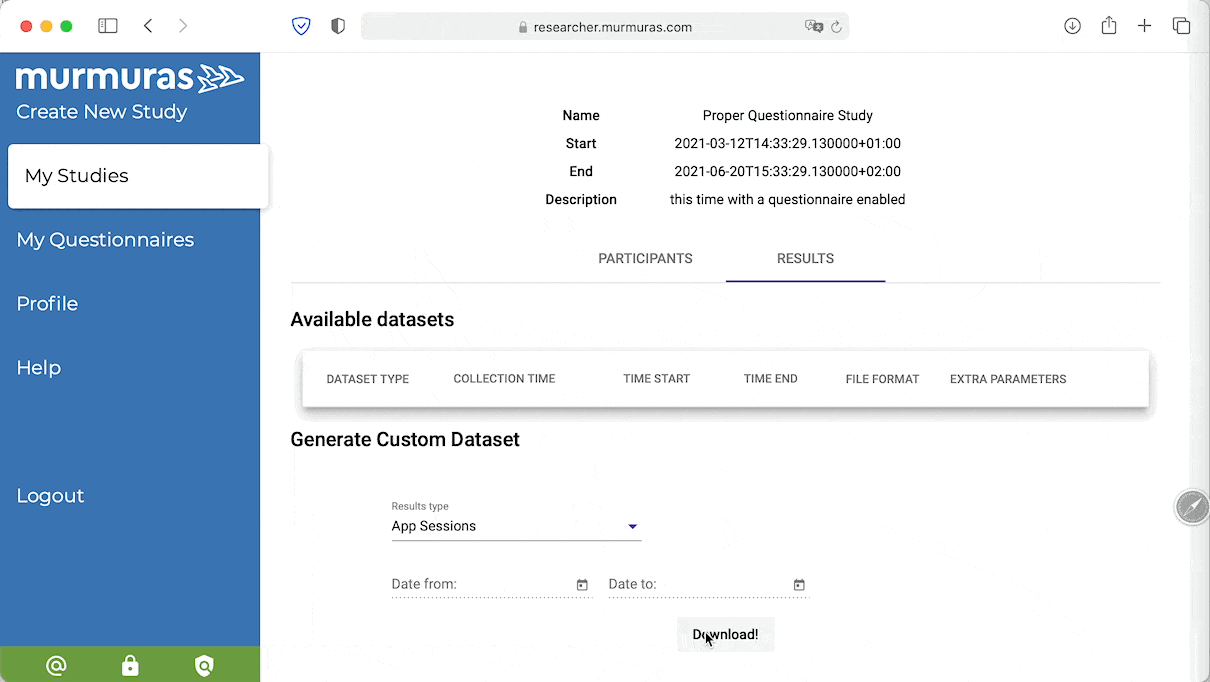
Lade deine Daten aus dem Murmuras Forscher*innen Portal runter. Du kannst aus verschiedenen Formaten und unterschiedlicher Granularität wählen. Wähle "App-Sessions" und klick dann auf Download. Die Daten werden im CSV-Format heruntergeladen. Verschiebe die Datei aus dem Download-Ordner in deinen Projektordner.
Arbeitsverzeichnis einstellen#
Jetzt legen wir deinen Projektordner als Arbeitsverzeichnis von R fest: Kopier den Pfad zu deinem Projektordner in die Klammern hinter "path <-" im grauen Codeblock unten. Klick anschließend auf den kleinen grünen Pfeil in der oberen rechten Ecke des grauen Codeblocks.
code# load required packages library(tidyverse) # set working directory path <- "/Users/Shared/Documents/r_intro/" knitr::opts_knit$set(root.dir = path)
Daten laden#
Lass uns die Daten in R laden. Kopier den Namen deines Datensatzes zwischen die Klammern in der Funktion read.csv() im Codeabschnitt unten. Drück den grünen Pfeil.
code# load data app_sessions <- read.csv("study_Pet_Study_app_sessions_2021-05-10.csv") # load demographics for later demographics <- read.csv("Pet_Study_demographics__2021-06-07.csv") # remove column with row numbers app_sessions <- app_sessions[2:ncol(app_sessions)] demographics <- demographics[2:ncol(demographics)]
Daten prüfen#
Es ist eine gute Idee, die Daten vor der Analyse zu prüfen, um alle verfügbaren Informationen zu verstehen. Drück den grünen Pfeil.
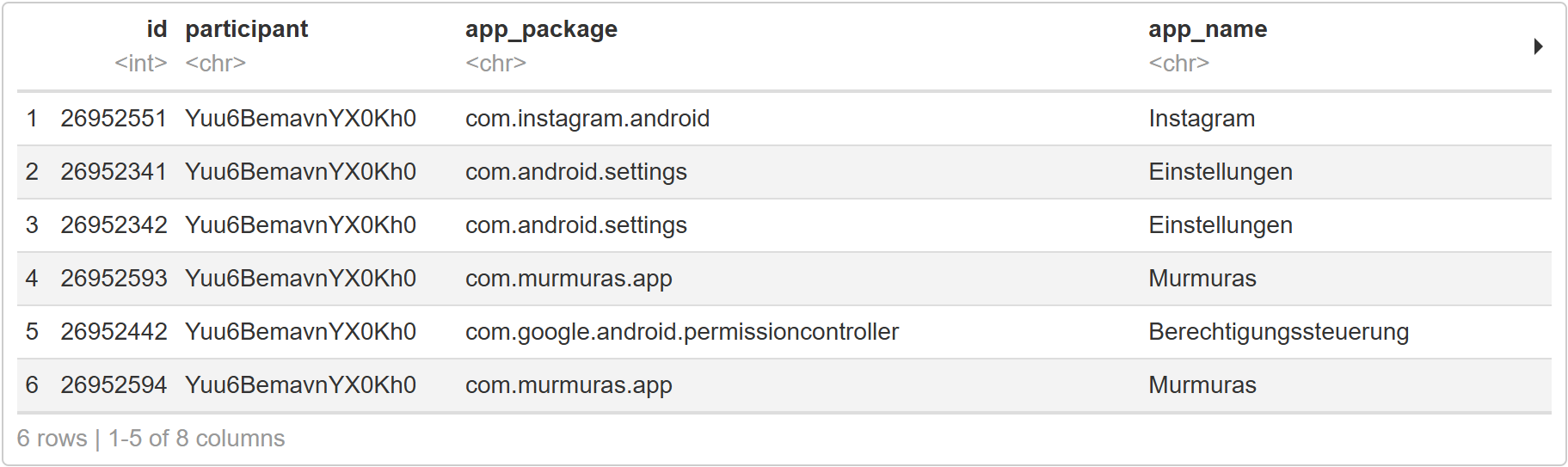
code# show the first few rows of the dataset head(app_sessions)
code# show the last few rows of the dataset tail(app_sessions)
code# show column names of the dataset colnames(app_sessions)

code# number of participants length(unique(app_sessions$participant))

Wie du siehst, besteht der Datensatz aus 8 Spalten:
1. ID: Jede einzelne App-Sitzung erhält eine eindeutige ID.
2. participant: Diese Zeichenfolge ist für jeden Teilnehmerin spezifisch und kann als ID verwendet werden.
3. granularity: Wir haben beim Herunterladen der Daten die Tagesgranularität gewählt. Das bedeutet, dass die gesammelten Daten, z.B. die App-Nutzungszeit, (siehe Spalte duration) pro Tag aggregiert werden.
4. app_package: Dieser String identifiziert die Apps eindeutig, app_names können je nach Sprache unterschiedlich sein, app_package ist universell.
5. app_name: Der non-universelle Name der App.
6. start_time: Die Zeit, zu der die Person begonnen hat, die App zu nutzen.
7. end_time: Der Zeitpunkt, an dem die Person die App wieder geschlossen hat.
8. duration: Die Zeit, die die App genutzt wurde, in Sekunden.
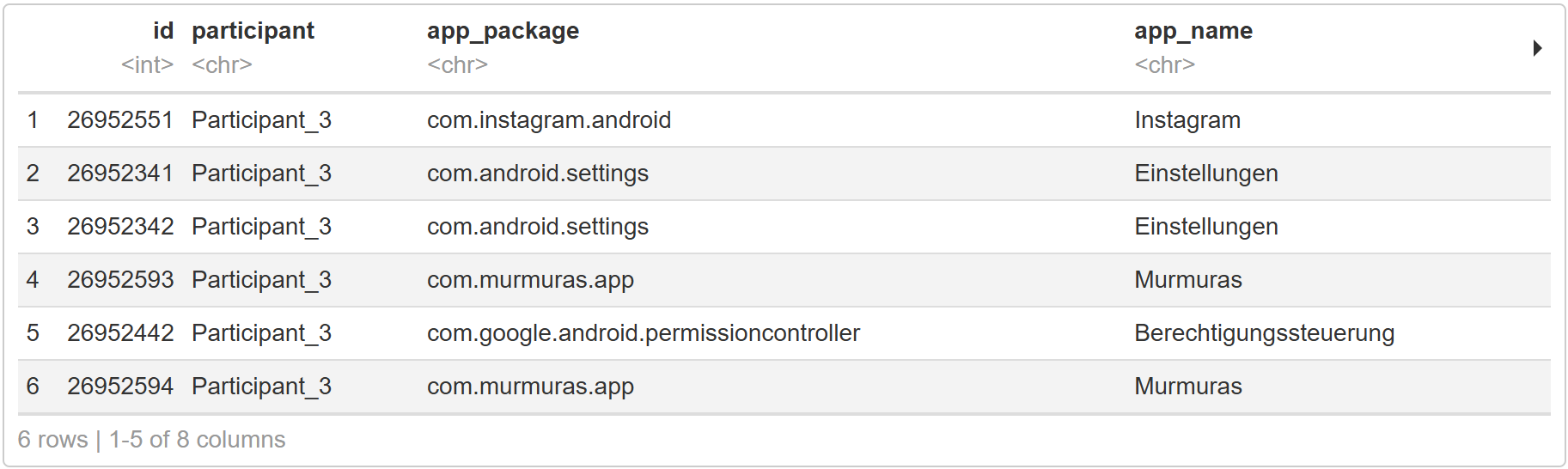
Teilnehmer*innen umbenennen#
Mit dem Teilnehmer*innen-Code kann man nicht so gut arbeiten, deshalb benennen wir ihn um.
codefor (i in 1:length(unique(app_sessions$participant))){ current_pp <- unique(app_sessions$participant)[i] app_sessions <- app_sessions %>% mutate(participant = ifelse(participant == current_pp, paste0("Participant_",i), participant)) # you will need this later! demographics <- demographics %>% mutate(code = ifelse(code == current_pp, paste0("Participant_",i), code)) } head(app_sessions)
App-Starts pro Teilnehmer*in und Tag#
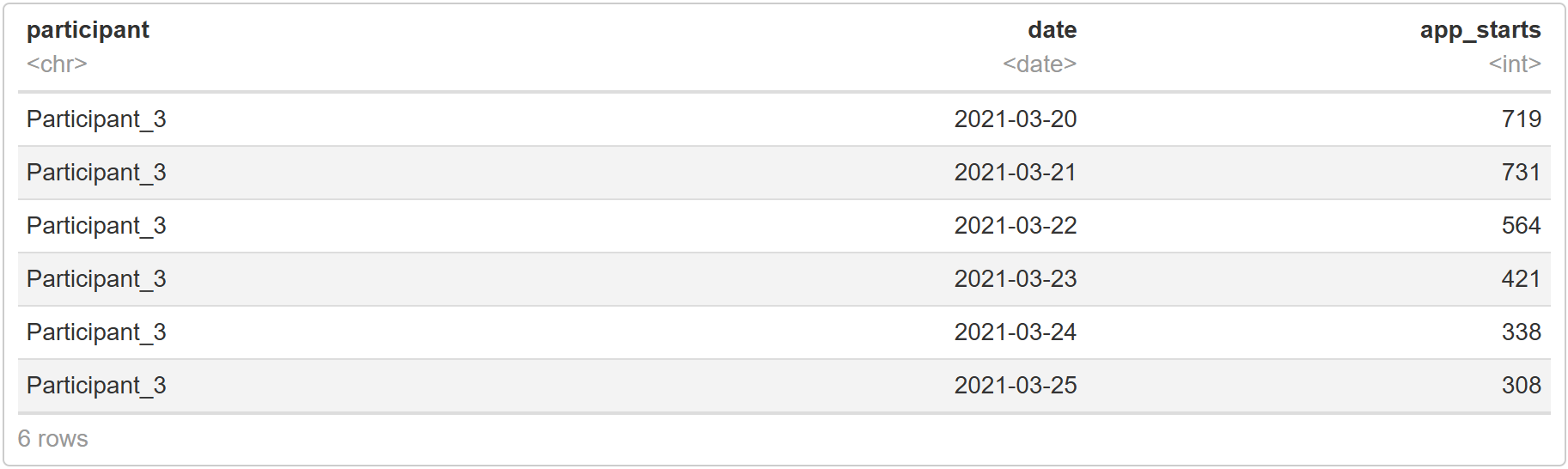
Du solltest überprüfen, wie viele Tage jeder Teilnehmerin an der Studie teilgenommen hat, insbesondere wenn die Einschlusskriterien deiner Studie eine Mindestanzahl von Tagen erfordern. Die Überprüfung der Anzahl der App-Starts pro Tag und Teilnehmerin hilft auch, Ausreißerinnen zu identifizieren.
code# add columns with date of app start app_sessions$date <- as.Date(app_sessions$start_time) # n user days user_days <- app_sessions %>% select(participant, date) %>% group_by(participant) %>% summarise(user_days = n_distinct(date)) head(user_days)

code# app starts per user per day app_starts <- app_sessions %>% group_by(participant,date) %>% summarise(app_starts = n_distinct(start_time)) head(app_starts)
Meistgenutzte Apps#
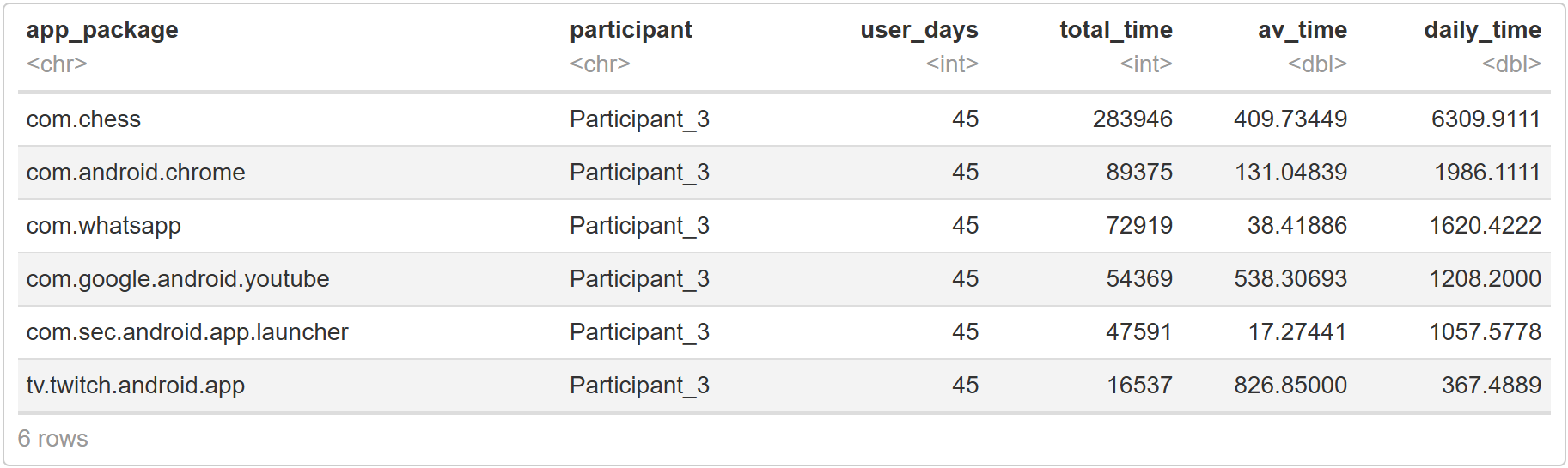
Als nächstes untersuchen wir, welche Apps am meisten genutzt wurden. Es gibt verschiedene Möglichkeiten, die App-Nutzung zu quantifizieren und zu bewerten. Hier berechnen wir die durchschnittliche tägliche Nutzungsdauer (unter Verwendung der zuvor berechneten Nutzungstage), sowie die Gesamtnutzungsdauer und die durchschnittliche Dauer einer App-Sitzung. Die Dauer wird in Sekunden angegeben.
codeapp_sessions <- app_sessions %>% group_by(participant) %>% mutate(user_days = n_distinct(date)) %>% # save column with user days to dataset filter(user_days > 0) # change this if you only want to include participants who participated for a certain amount of days # most used apps per user favourite_apps <- app_sessions %>% group_by(app_package, participant, user_days) %>% summarise(total_time = sum(duration), av_time = mean(duration)) %>% mutate(daily_time = total_time/user_days) %>% arrange(desc(daily_time)) head(favourite_apps)
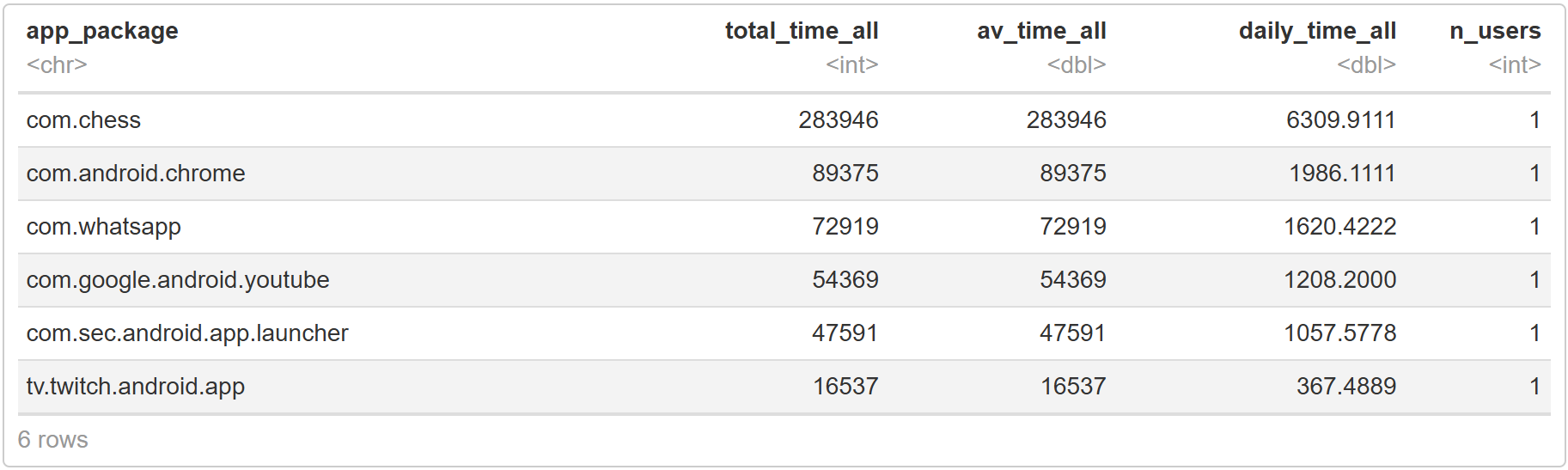
code# top apps across users top_apps <- favourite_apps %>% group_by(app_package) %>% summarise(total_time_all = sum(total_time), av_time_all = mean(total_time), daily_time_all = total_time_all/sum(user_days), n_users = n_distinct(participant)) %>% arrange(desc(daily_time_all)) # print the first few rows head(top_apps)
Frauen und Männer vergleichen#
Schauen wir mal, ob es Unterschiede zwischen Männern und Frauen gibt, ähnlich wie wir es in einem vorherigen Blogbeitrag gemacht haben. Dazu müssen wir die Daten aus dem Onboarding-Fragebogen in R laden. Du findest diesen Datensatz im Forscher*innen Portal auf der Murmuras Plattform. Lade ihn runter und speichern ihn in deinem Projektordner.
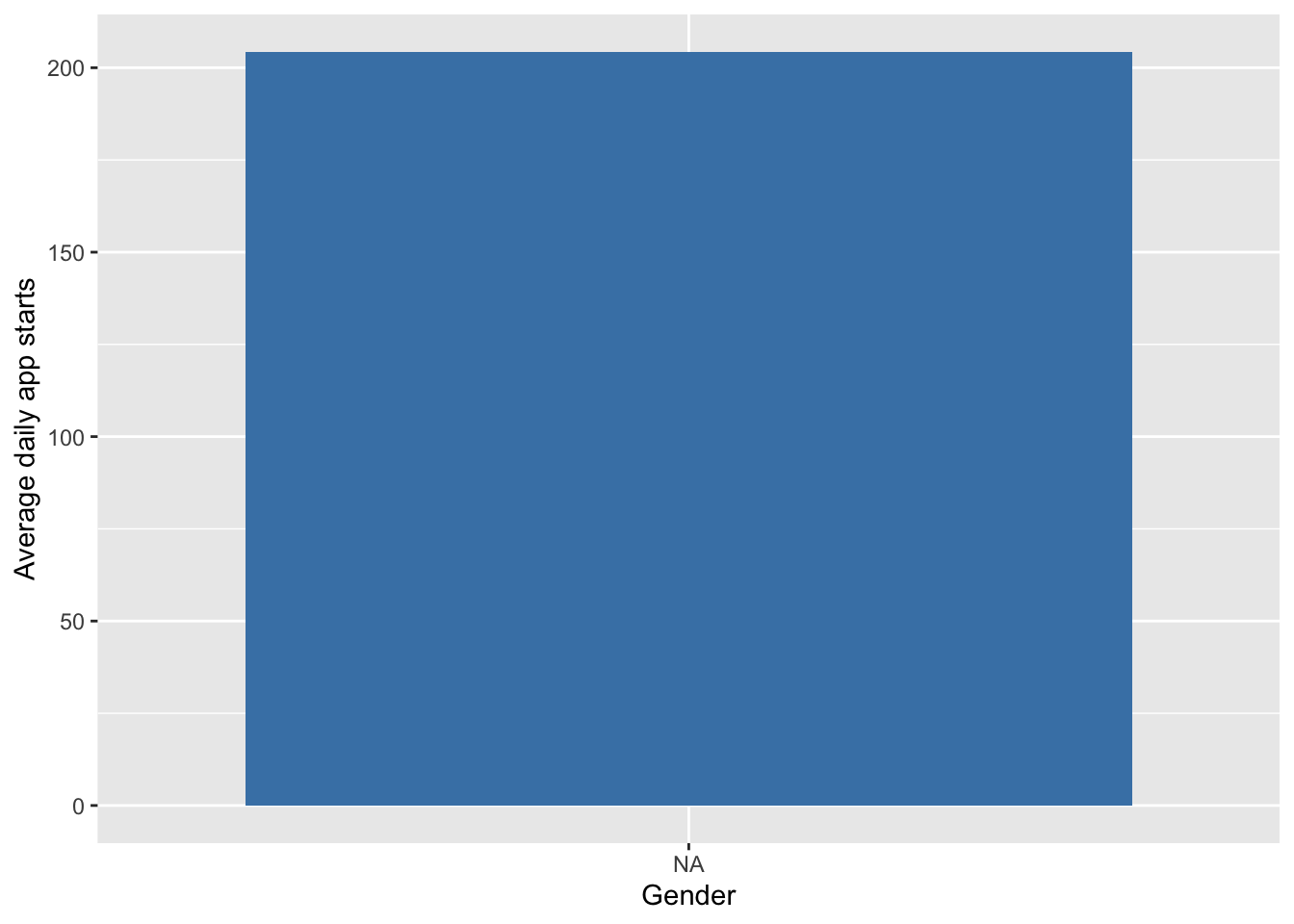
Damit die Daten richtig formatiert sind, haben wir sie schon am Anfang in unsere R-Umgebung geladen. Um Männer mit Frauen zu vergleichen, wähle die Variable gender aus. Du kannst auch andere Gruppen vergleichen, z.B. nach Alter getrennt. Als Nächstes konkatenieren (d. h. verknüpfen) wir die Variable gender mit unserem App-Sessions-Datensatz. R kann das ganz einfach mit Hilfe des Teilnehmer*innencodes tun. Jetzt sind wir bereit, die Anzahl der App-Starts und die Top-Apps von Männern und Frauen zu vergleichen. Gibt es Unterschiede in deiner Stichprobe?
code# what information is included? colnames(demographics) gender_df <- demographics %>% select(code, gender) # concatenate datasets app_sessions_gender <- app_sessions %>% left_join(gender_df, by = c("participant" = "code" ) ) # average amount of app starts apps_starts_gender <- app_sessions_gender %>% group_by(gender, participant, date) %>% summarise(app_starts = n_distinct(start_time)) %>% group_by(gender) %>% summarise(av_daily_app_starts = mean(app_starts)) # let's plot this! ggplot(data = apps_starts_gender, aes(x = gender, y = av_daily_app_starts)) + geom_bar(stat="identity", fill="steelblue") + labs(x = "Gender", y = "Average daily app starts")
code# top apps men men_favourite_apps <- app_sessions_gender %>% filter(gender == "male") %>% group_by(app_package, user_days) %>% summarise(total_time = sum(duration), av_time = mean(duration)) %>% mutate(daily_time = total_time/user_days) %>% arrange(desc(daily_time)) head(men_favourite_apps)

code# top apps women women_favourite_apps <- app_sessions_gender %>% filter(gender == "female") %>% group_by(app_package, user_days) %>% summarise(total_time = sum(duration), av_time = mean(duration)) %>% mutate(daily_time = total_time/user_days) %>% arrange(desc(daily_time)) head(women_favourite_apps)
Monatliche App-Nutzungsdauer#
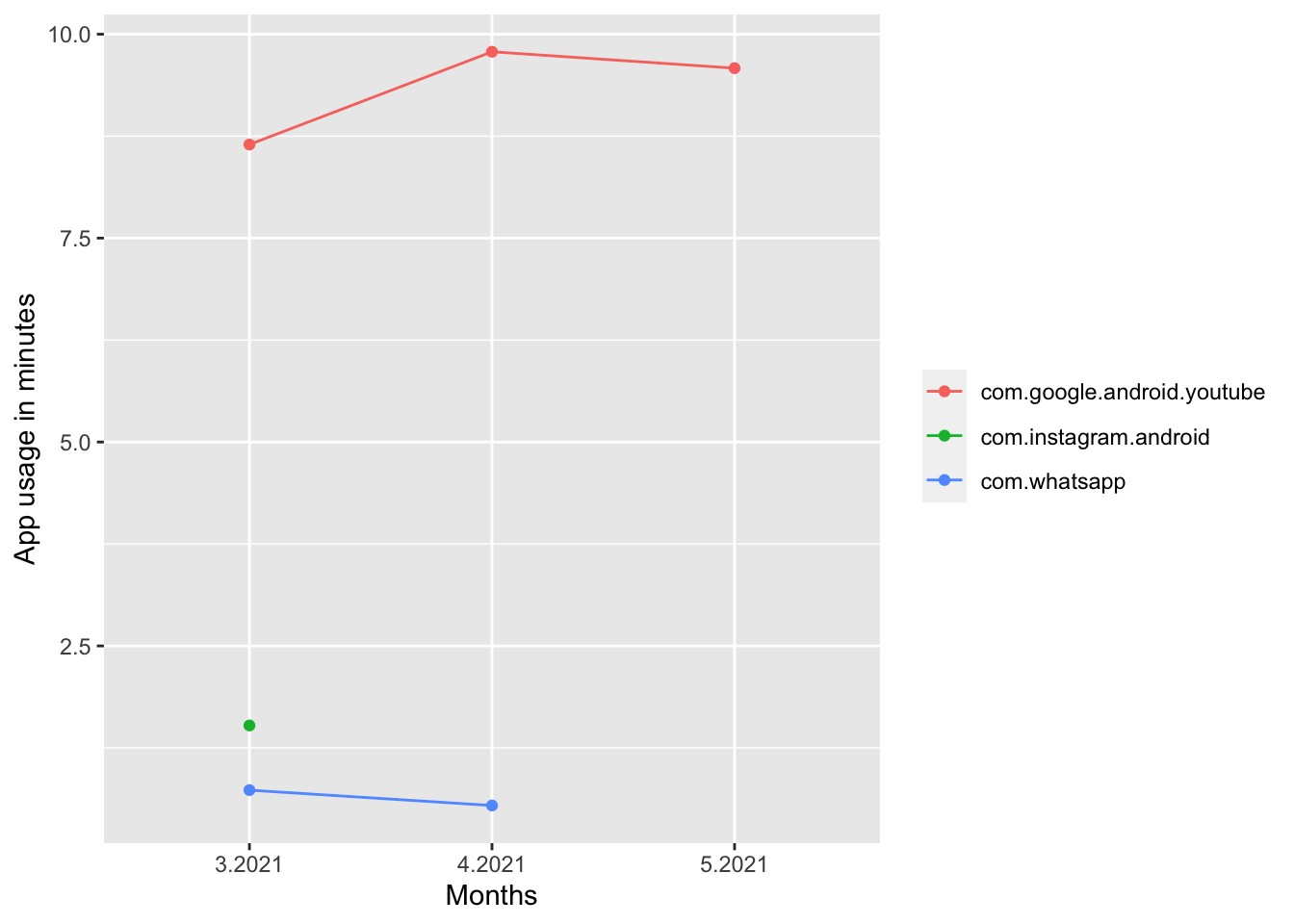
Als letzten Punkt in diesem ersten Tutorial analysieren wir die Entwicklung der durchschnittlichen App-Nutzungsdauer von WhatsApp, Instagram und YouTube über die ganze Studiendauer. Wir müssen unsere Daten so filtern, dass der neue Datensatz nur die Apps enthält, die wir betrachten wollen. In der Regel ist es besser, app_package anstelle von app_name zu verwenden, da app_package in allen Sprachen gleich ist. Es ist leicht zu erkennen, welches app_package zu welcher App gehört, wenn nicht, kannst du dir die Google Playstore URL ansehen. Als Beispiel: Die URL für die Youtube-App lautet: https://play.google.com/store/apps/details?id=com.google.android.youtube, und com.google.android.youtube ist der Name des app_package. Als nächstes fügen wir eine neue Variable (d.h. eine neue Spalte) mit dem entsprechenden Monat zu den Daten hinzu. Wir berechnen die durchschnittliche monatliche Nutzungsdauer für jeden Teilnehmerin und stellen diese schließlich mit der Zeit auf der x-Achse und der Nutzungsdauer auf der y-Achse dar. Dies ist nur ein Beispiel, wie du deine Daten visuell darstellen kannst. Es gibt viele weitere Visualisierungsmöglichkeiten, je nachdem, was du hervorheben willst und was deine Designvorlieben sind.
code# filter data filtered_data <- app_sessions %>% filter(app_package %in% c("com.instagram.android", "com.whatsapp", "com.google.android.youtube")) %>% # add month & add year in case your data spans more than one year mutate(month = lubridate::month(date, abbr = T), year = lubridate::year(date)) %>% arrange(date) # compute monthly average usage duration monthly_usage <- filtered_data %>% group_by(month, year, app_package) %>% summarise(av_monthly_time = mean(duration)/60) %>% # in minutes # create month_year variable arrange(month) %>% mutate(month_year = paste(month,year, sep = ".")) # plot the usage duration of each app over time ggplot(data=monthly_usage, aes(x=month_year, y=av_monthly_time, group=app_package)) + geom_line(aes(color=app_package)) + geom_point(aes(color=app_package)) + labs(x = "Months", y = "App usage in minutes") + theme(legend.title = element_blank())
Werde selber kreativ!#
Ich hoffe, diese kleine Einführung hat dir einen ersten Eindruck davon vermittelt, wie unsere Daten organisiert sind. Denk daran, dass dies nur ein kleines Beispiel ist, und dass es noch viel mehr zu entdecken und aus deinen Daten herauszuholen gibt. In einem späteren Blogbeitrag werde ich zeigen, wie du die demografischen Fragen, die Teil des Onboarding-Fragebogens sind, sowie die anderen Datenaggregationsarten, d.h. das Breitformat und das Langformat, weiter nutzen kannst. Sie haben alle unterschiedliche Vorteile und es hängt von der konkreten Forschungsfrage ab, welche du für deine Analysen verwenden solltest. Meiner Meinung nach ist das App-Session-Aggregationsformat das intuitivste, weshalb ich es zum Einstieg empfehle, um dich mit deinen Daten vertraut zu machen.
Kontaktiere mich, wenn du Fragen zu diesem Beitrag hast oder Hilfe bei deiner Analyse brauchst!
Du kannst den vollständigen R-Code und den Übungsdatensatz hier herunterladen: zip-file
About the author
Qais Kasem
Related Posts

Analysieren von Smartphone-Nutzungsdaten mit R - Teil 2: Langformat

Kostenlose Smartphone-App & Plattform um menschliches Verhalten zu erforschen für Studierende und Forscher*innen
