
Analyzing smartphone usage data with R - Part 1: App sessions
We are going to show you how to analyze app usage data from the Murmuras Platform in R. You will:
1. Identify the most-used apps in your sample
2. Compare app usage of women vs men
3. Plot monthly mean app usage duration of WhatsApp, Instagram and YouTube
We use RStudio as our work environment. If you want to follow along in RStudio, just download this zip-file containg the Rmd-file and practice datasets, copy it to your project directory, and open it in RStudio.
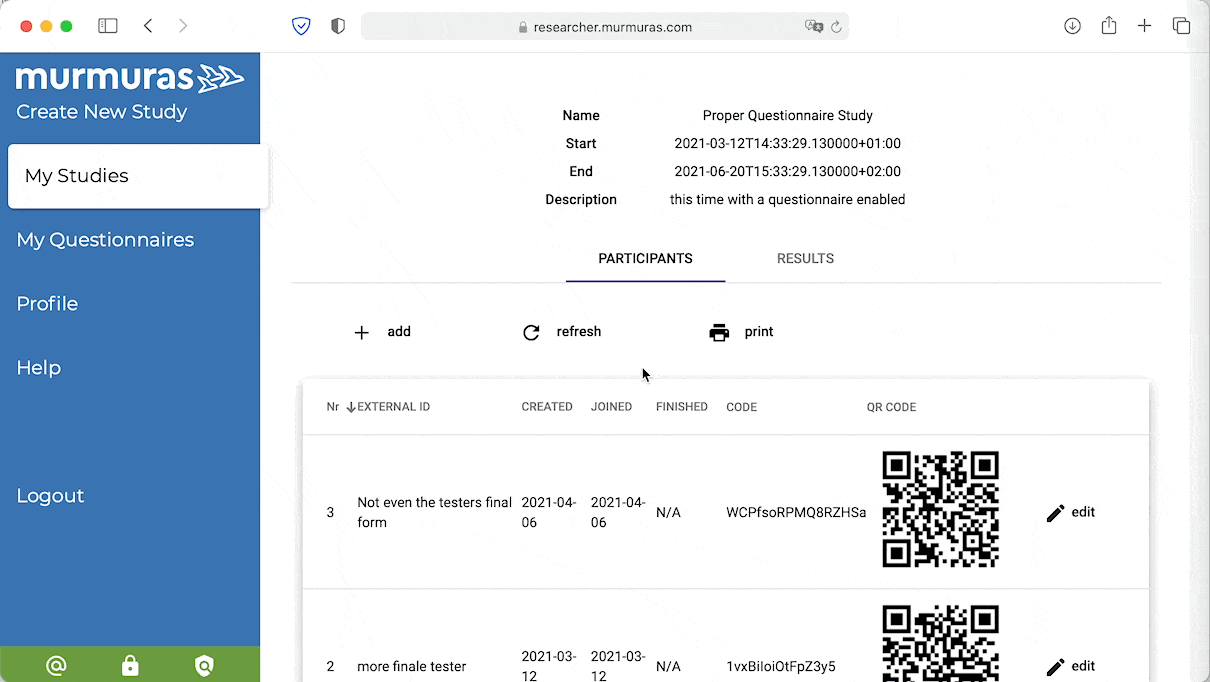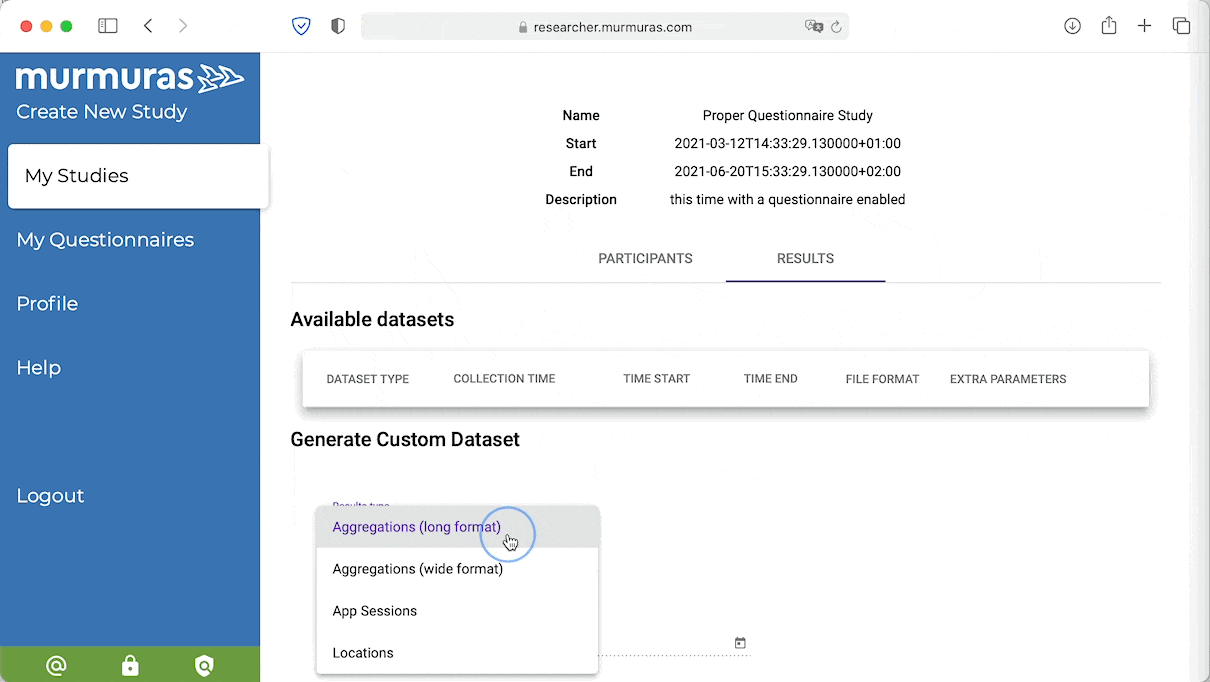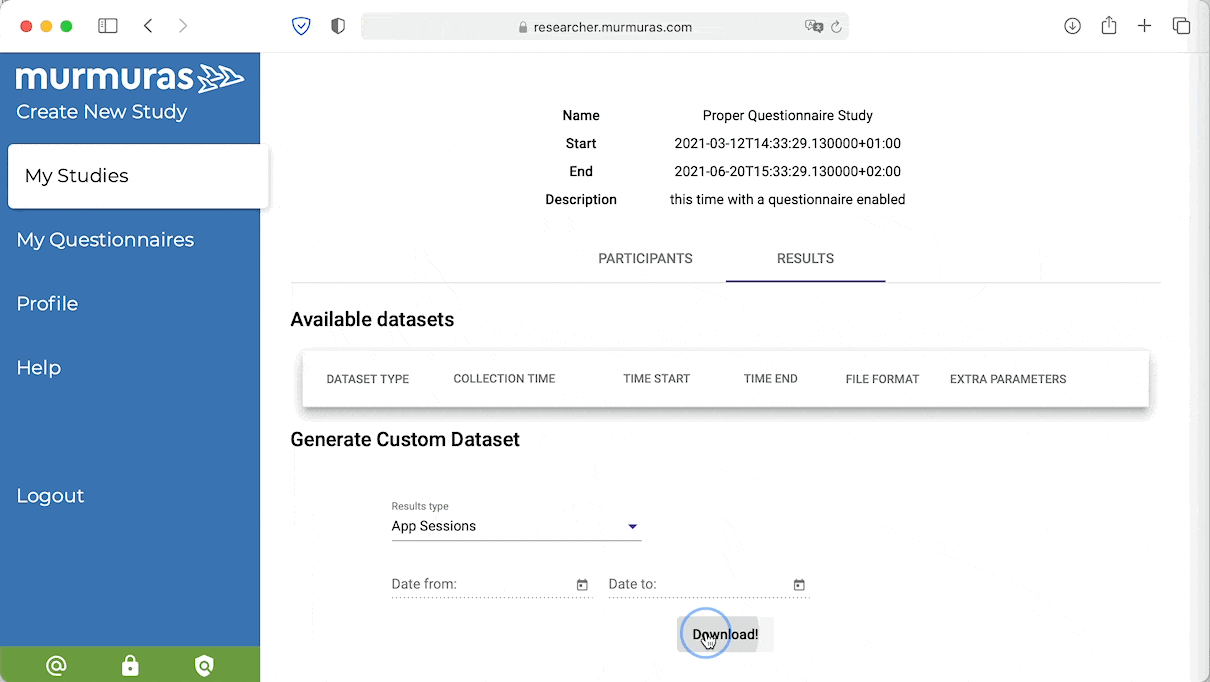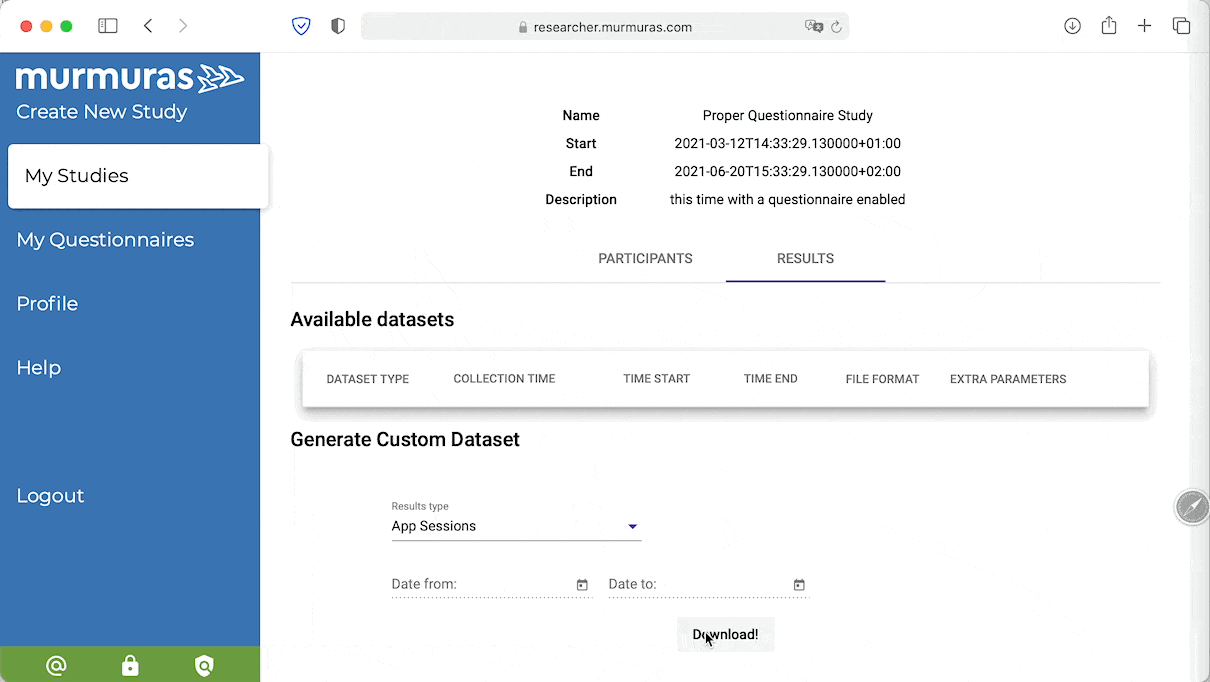
Download your data from the Murmuras Researcher Portal. You can choose from different formats and different granularity. Choose “App sessions”, then click download. The data will be downloaded in CSV-format. Move the file from your download folder to your project folder.
Set working directory#
Now, we are going to set your project folder as R’s working directory: Copy the path to your project folder into the parentheses behind "path <-" in the gray code block below. Afterwards, click the little green arrow in the upper right corner of the gray code block.
code# load required packages library(tidyverse) # set working directory path <- "/Users/Shared/Documents/r_intro/" knitr::opts_knit$set(root.dir = path)
Load data#
Let’s load the data into R. Copy the name of your dataset between the parentheses in the read.csv() function in the code chunk below. Press the green arrow.
code# load data app_sessions <- read.csv("study_Pet_Study_app_sessions_2021-05-10.csv") # load demographics for later demographics <- read.csv("Pet_Study_demographics__2021-06-07.csv") # remove column with row numbers app_sessions <- app_sessions[2:ncol(app_sessions)] demographics <- demographics[2:ncol(demographics)]
Inspect data#
It is a good idea to inspect the data before analyzing it, to understand all available information. Press the green arrow.
code# show the first few rows of the dataset head(app_sessions)
code# show the last few rows of the dataset tail(app_sessions)
code# show column names of the dataset colnames(app_sessions)

code# number of participants length(unique(app_sessions$participant))

As you can see, the data consists of eight columns:
1. id: Each individual app session gets a unique ID.
2. participant: This string is specific to every participant and can be used as an identifier.
3. granularity: We chose daily granularity when downloading the data. This means that the collected data, e.g. app usage time, (see column duration) is aggregated per day.
4. app_package: This string uniquely identifies the apps, app_names can be different depending on the language, app_package is universal.
5. app_name: The non-universal name of the app.
6. start_time: The time the person started to use the app.
7. end_time: The time the person closed the app again.
8. duration: The time the app was used in seconds.
Rename participants#
The participant code can be difficult to work with, so we are going to rename them.
codefor (i in 1:length(unique(app_sessions$participant))){ current_pp <- unique(app_sessions$participant)[i] app_sessions <- app_sessions %>% mutate(participant = ifelse(participant == current_pp, paste0("Participant_",i), participant)) # you will need this later! demographics <- demographics %>% mutate(code = ifelse(code == current_pp, paste0("Participant_",i), code)) } head(app_sessions)
App starts per user per day#
You should check how many days each of your users participated in the study, especially if your study’s inclusion criteria require a minimum amount of days. Checking the amount of app starts per day per user also helps to identify outliers.
code# add columns with date of app start app_sessions$date <- as.Date(app_sessions$start_time) # n user days user_days <- app_sessions %>% select(participant, date) %>% group_by(participant) %>% summarise(user_days = n_distinct(date)) head(user_days)

code# app starts per user per day app_starts <- app_sessions %>% group_by(participant,date) %>% summarise(app_starts = n_distinct(start_time)) head(app_starts)
Top apps#
Next, we are going to explore which apps were used most. There are different ways to quantify and rank app usage. Here, we calculate the daily average usage duration (using the previously computed user days), as well as total overall usage duration and the average duration of one app session. Duration is given in seconds.
codeapp_sessions <- app_sessions %>% group_by(participant) %>% mutate(user_days = n_distinct(date)) %>% # save column with user days to dataset filter(user_days > 0) # change this if you only want to include participants who participated for a certain amount of days # most used apps per user favourite_apps <- app_sessions %>% group_by(app_package, participant, user_days) %>% summarise(total_time = sum(duration), av_time = mean(duration)) %>% mutate(daily_time = total_time/user_days) %>% arrange(desc(daily_time)) head(favourite_apps)
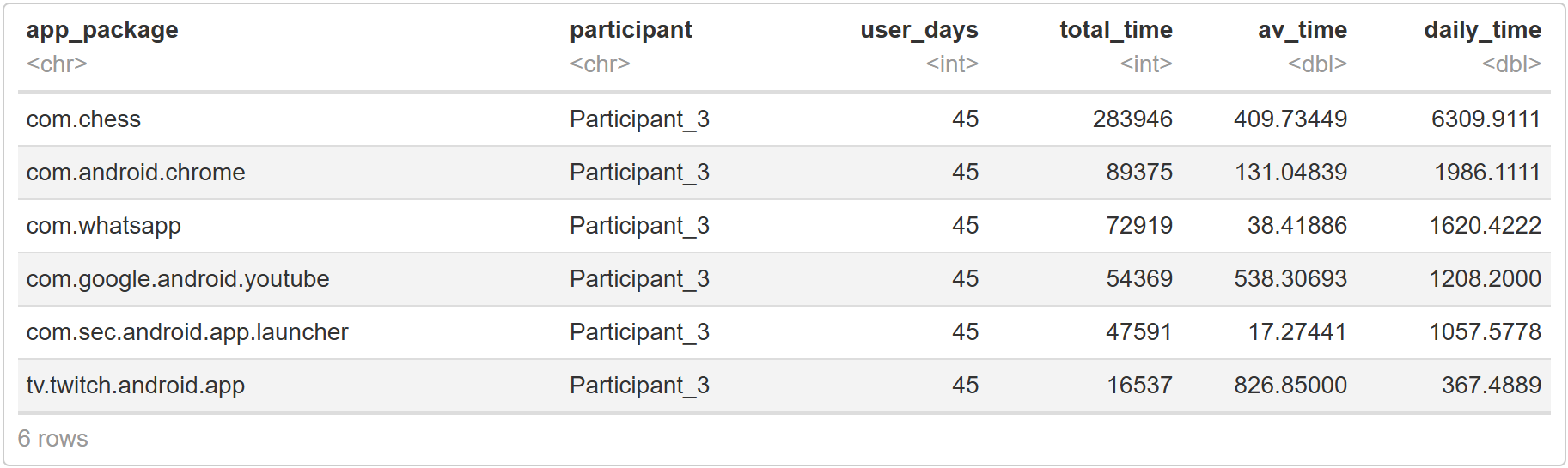
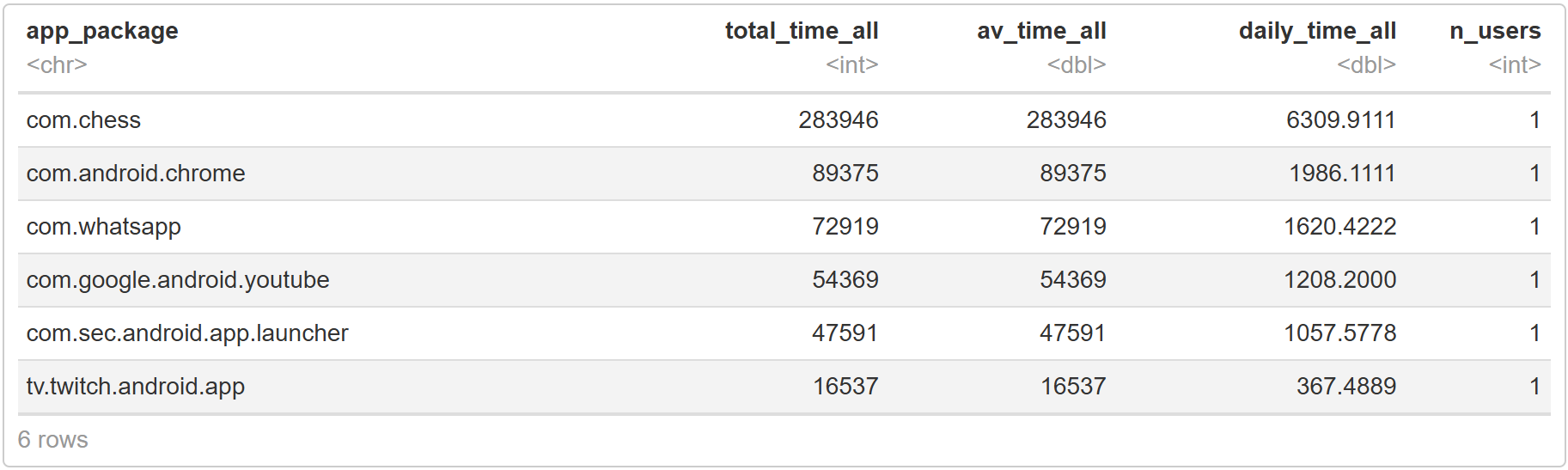
code# top apps across users top_apps <- favourite_apps %>% group_by(app_package) %>% summarise(total_time_all = sum(total_time), av_time_all = mean(total_time), daily_time_all = total_time_all/sum(user_days), n_users = n_distinct(participant)) %>% arrange(desc(daily_time_all)) # print the first few rows head(top_apps)
Compare men and women#
Let’s see if there are differences between men and women, similar to how we did it in a previous blog post. To do so, we have to load the data from the onboarding questionnaire into R. You can find this dataset in the Researcher Portal on the Murmuras Platform. Download and save it to your project folder.
Remember that we already loaded our second csv-file into our R environment at the beginning. To compare men to women, select the gender variable. You can also compare other groups, e.g. divided by age. Next, concatenate (i.e. link) the gender variable with our app sessions dataset. R can do this easily with the participant code. Now we are ready to compare the number of app starts and the top apps of men and women. Are there differences in your sample?
code# what information is included? colnames(demographics) gender_df <- demographics %>% select(code, gender) # concatenate datasets app_sessions_gender <- app_sessions %>% left_join(gender_df, by = c("participant" = "code" ) ) # average amount of app starts apps_starts_gender <- app_sessions_gender %>% group_by(gender, participant, date) %>% summarise(app_starts = n_distinct(start_time)) %>% group_by(gender) %>% summarise(av_daily_app_starts = mean(app_starts)) # let's plot this! ggplot(data = apps_starts_gender, aes(x = gender, y = av_daily_app_starts)) + geom_bar(stat="identity", fill="steelblue") + labs(x = "Gender", y = "Average daily app starts")
code# top apps men men_favourite_apps <- app_sessions_gender %>% filter(gender == "male") %>% group_by(app_package, user_days) %>% summarise(total_time = sum(duration), av_time = mean(duration)) %>% mutate(daily_time = total_time/user_days) %>% arrange(desc(daily_time)) head(men_favourite_apps)

code# top apps women women_favourite_apps <- app_sessions_gender %>% filter(gender == "female") %>% group_by(app_package, user_days) %>% summarise(total_time = sum(duration), av_time = mean(duration)) %>% mutate(daily_time = total_time/user_days) %>% arrange(desc(daily_time)) head(women_favourite_apps)
Monthly app usage duration#
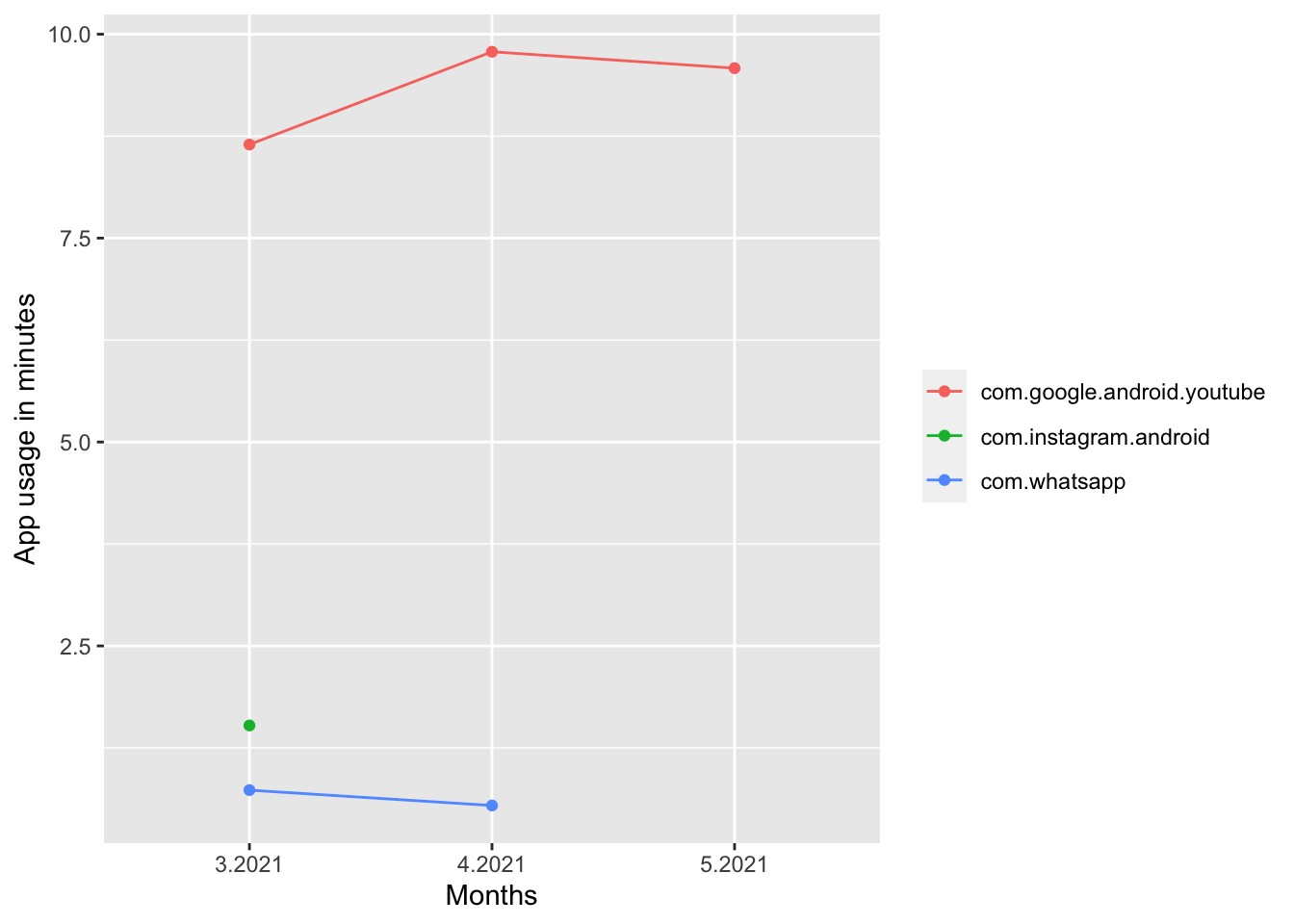
Finally, we are interested in the development of mean app usage duration of WhatsApp, Instagram and YouTube over time. We have to filter our data so that the new dataset only includes the apps we want to look at. It is usually better to use app_package instead of app_name, because app_package is the same in all languages. It is easy to identify which app_package belongs to which app, if not you can look at the Google Playstore URL. As an example: the URL for the Youtube app is: https://play.google.com/store/apps/details?id=com.google.android.youtube, and com.google.android.youtube is the app package name. Next, we add a new variable (i.e. a new column) with the corresponding month to the data. We compute the mean monthly usage duration for each participant and plot these with time on the x-axis and usage duration on the y-axis. This is just an example of how you can visually plot your data, there are many other ways depending on what you are trying to highlight and also what your design preferences are.
code# filter data filtered_data <- app_sessions %>% filter(app_package %in% c("com.instagram.android", "com.whatsapp", "com.google.android.youtube")) %>% # add month & add year in case your data spans more than one year mutate(month = lubridate::month(date, abbr = T), year = lubridate::year(date)) %>% arrange(date) # compute monthly average usage duration monthly_usage <- filtered_data %>% group_by(month, year, app_package) %>% summarise(av_monthly_time = mean(duration)/60) %>% # in minutes # create month_year variable arrange(month) %>% mutate(month_year = paste(month,year, sep = ".")) # plot the usage duration of each app over time ggplot(data=monthly_usage, aes(x=month_year, y=av_monthly_time, group=app_package)) + geom_line(aes(color=app_package)) + geom_point(aes(color=app_package)) + labs(x = "Months", y = "App usage in minutes") + theme(legend.title = element_blank())
Make it your own!#
I hope this little introduction gave you a first idea of how the data is organized. Keep in mind, that this is only a limited example and that there is much more to discover and extract from your data. In a later blog post, I am going to show you how to make further use of the demographic questions that are part of the onboarding questionnaire, as well as the other data aggregation types, i.e. the wide-format and the long-format. They all have different advantages and it depends on your research question which one you should use for your analyses. In my opinion, the app session aggregation format is the most intuitive one, which is why I recommend it when you want to get acquainted with your data.
Get in touch if you have any questions regarding this post or if you need help with your particular analysis!
You can download the whole R-code and practice dataset here: zip-file
About the author
Qais Kasem
Related Posts

Analyzing smartphone usage data with R - Part 2: Long Format

Free smartphone app & platform to study human behavior for students and researchers
